Crawling and Scraping
Website Crawling: A Guide on Everything You Need to Know

Understanding website crawling and how search engines crawl and index websites can be a confusing topic. Everyone does it a little bit differently, but the overall concepts are the same. Here is a quick breakdown of things you should know about how search engines crawl your website. (I’m not getting into the algorithms, keywords or any of that stuff, simply how search engines crawl sites.)
So what is website crawling?
Website Crawling is the automated fetching of web pages by a software process, the purpose of which is to index the content of websites so they can be searched. The crawler analyzes the content of a page looking for links to the next pages to fetch and index.
What types of crawls are there?
Two of the most common types of crawls that get content from a website are:
- Site crawls are an attempt to crawl an entire site at one time, starting with the home page. It will grab links from that page, to continue crawling the site to other content of the site. This is often called “Spidering”.
- Page crawls, which are the attempt by a crawler to crawl a single page or blog post.
Are there different types of crawlers?
There definitely are different types of crawlers. But one of the most important questions is, “What is a crawler?” A crawler is a software process that goes out to websites and requests the content as a browser would. After that, an indexing process actually picks out the content it wants to save. Typically the content that is indexed is any text visible on the page.
Different search engines and technologies have different methods of getting a website’s content with crawlers:
- Crawls can get a snapshot of a site at a specific point in time, and then periodically recrawl the entire site. This is typically considered a “brute force” approach as the crawler is trying to recrawl the entire site each time. This is very inefficient for obvious reasons. It does, though, allow the search engine to have an up-to-date copy of pages, so if the content of a particular page changes, this will eventually allow those changes to be searchable.
- Single page crawls allow you to only crawl or recrawl new or updated content. There are many ways to find new or updated content. These can include sitemaps, RSS feeds, syndication and ping services, or crawling algorithms that can detect new content without crawling the entire site.
Can crawlers always crawl my site?
That’s what we strive for at OutsourceIT, but isn’t always possible. Typically, any difficulty crawling a website has more to do with the site itself and less with the crawler attempting to crawl it. The following issues could cause a crawler to fail:
- The site owner denies indexing and or crawling using a robots.txt file.
- The page itself may indicate it’s not to be indexed and links not followed (directives embedded in the page code). These directives are “meta” tags that tell the crawler how it is allowed to interact with the site.
- The site owner blocked a specific crawler IP address or “user-agent”.
All of these methods are usually employed to save bandwidth for the owner of the website, or to prevent malicious crawler processes from accessing the content. Some site owners simply don’t want their content to be searchable. One would do this kind of thing, for example, if the site was primarily a personal site, and not really intended for a general audience.
I think it is also important to note here that robots.txt and meta directives are really just a “gentlemen’s agreement”, and there’s nothing to prevent a truly impolite crawler from crawling. Many Crawlers are polite, and will not request pages that have been blocked by robots.txt or meta directives.
How do I optimize my website so it is easy to crawl?
There are steps you can take to build your website in such a way that it is easier for search engines to crawl it and provide better search results. The end result will be more traffic to your site, and enabling your readers to find your content more effectively.
Search Engine Accessibility Tips:
- Having an RSS feed or feeds so that when you create new content the search software can recognize new content and crawl it faster.
- Be selective when blocking crawlers using robots.txt files or meta tag directives in your content. Most blog platforms allow you to customize this feature in some way. A good strategy to employ is to let the search engines in that you trust, and block those you don’t.
- Building a consistent document structure. This means when you construct your HTML page that the content you want crawled is consistently in the same place under the same content section.
- Having content and not just images on a page. Search engines can’t find an image unless you provide text or alt tag descriptions for that image.
- Try (within the limits of your site design) to have links between pages so the crawler can quickly learn that those pages exist. If you’re running a blog, you might, for example, have an archive page with links to every post. Most blogging platforms provide such a page. A sitemap page is another way to let a crawler know about lots of pages at once.
To learn more about configuring robots.txt and how to manage it for your site, visit http://www.robotstxt.org/. We want you to be a successful blogger, and understanding website crawling is one of the most important steps.
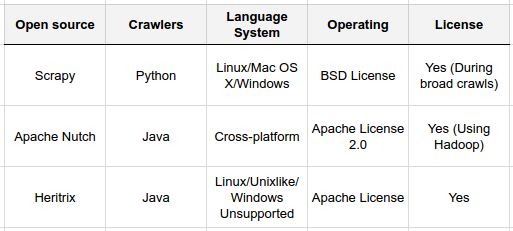
terms of various parameters (IJSER)







Nudefusion AI App Review
Blur Card – Crypto Cards with Hidden Fees
ControlNet: Revolutionizing Neural Control in AI Image Generation
PayPal Sports Betting Guide for Beginners

Open-Source GPT-3/4 LLM Alternatives to Try in 2026
Nudefusion AI App Review
ControlNet: Revolutionizing Neural Control in AI Image Generation