News
Open-Source GPT-3/4 LLM Alternatives to Try in 2026

Do you want to unlock the power of natural language processing without relying on hefty GPT-4 models?
If yes, then you’ve come to the right place! This blog post will discuss some open-source alternatives that can help you achieve the same results as GPT-3 or GPT-4 without the huge costs and resources required. So let’s explore these tools and see which one is best for you!
Our Top Free GPT Alternative AI/LLM models list:
- BERT by Google
- Alpaca-Lora (13b)
- Vicuna – NEW Tool (13b)
- OpenChatKit (13b)
- OPT by Meta
- Dolly 2.0
- AlexaTM by Amazon
- GPT-J and GPT-NeoX by EleutherAI
- Jurassic-1 language model by AI21 labs
- CodeGen by Salesforce
- Megatron-Turing NLG by NVIDIA and Microsoft
- LaMDA by Google
- BLOOM
- GLaM by Google
- Wu Dao 2.0
- Chinchilla by DeepMind
- EleutherAI
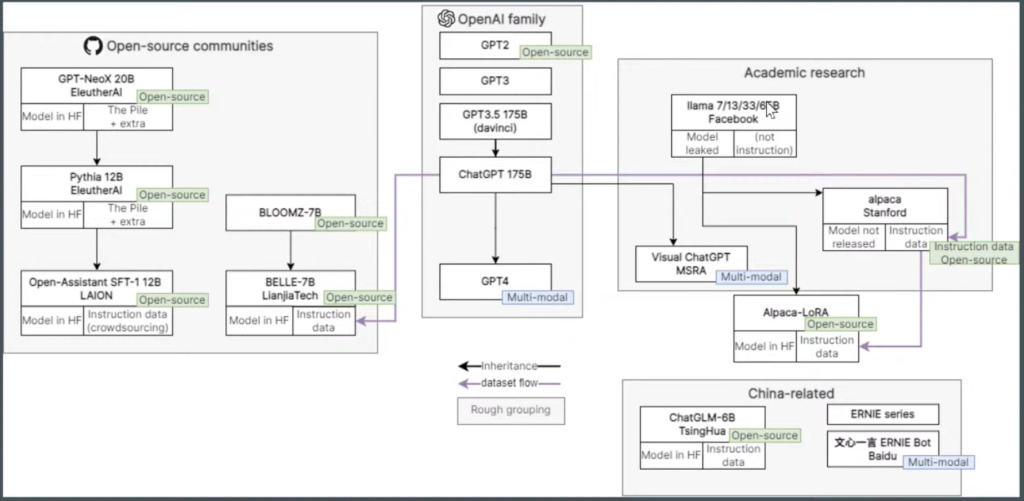
Introduction to GPT
In 2017, an article called “Attention is all you need” was published, which proposed a new architecture for neural networks called General Purpose Transformer (GPT). The novelty of this architecture was that it is based on a Multilayer Perceptron (MLP), which is a simple approximation of how neurons in the brain work at a biological level. To put it simply, MLP is a mathematical expression that can be differentiated, and in mathematics, anything that can be differentiated can be optimized for some utility function. MLP has been used for over half a century, and most of the scientific community was skeptical that it could be a promising path for research in the field of AI. However, the simplicity of MLP and a few improvements made a breakthrough possible.
As an architecture, GPT added the ability to have connections between different parts of the neural network and to assign different weights to input data through the attention mechanism. Thanks to the simplicity of implementation (matrix operations), it all started to work very well and scale. The final touch was that this GPT architecture works fantastically for the next token prediction task for language. Humanity has generated a sea of textual information during its existence, and if this dataset of all this text is correctly split, it contains both X (input data) and Y (output data) and is self-sufficient for training without a human. This is how Large Language Models (LLM) appeared, which optimize the function of what can be the next symbol in a sequence.
Moreover, in recent months, it has been found that most tasks in the world can be reduced to next token prediction, with which LLMs have started to cope well. If to describe it very inaccurately, the LLM/GPT architecture became possible because we have powerful GPU processors that were able to train very large but architecturally simple neural networks based on all the textual information in the world.
In other words, there has been a breakthrough in the field of artificial intelligence systems, which became possible due to:
- scientific apparatus that allowed this (GPT)
- a large dataset to learn from (“the internet” and all the information in it)
- the ability of modern processors to perform fast and scalable computations that were not possible before (GPU)
How does it work?
- Training: GPT models are pre-trained on vast amounts of text from the internet. This helps them develop an understanding of grammar, context, and semantics.
- Transformer Architecture: GPT utilizes the transformer architecture, which consists of multiple layers of self-attention mechanisms. These mechanisms allow the model to focus on different parts of the input sequence while generating output.
- Fine-tuning: After pre-training, specific tasks can be fine-tuned using domain-specific datasets or prompts. This helps adapt the model for different applications such as translation, summarization, or question answering.
- Language Generation: Once trained and fine-tuned, GPT models can generate human-like text based on a given prompt or context. They excel at generating creative content like stories and articles.
Popular OpenAI Solution – GPT-3/4
GPT-3 (Generative Pre-trained Transformer 3) is a large, autoregressive language model developed and released by OpenAI. It has been widely praised and adopted by businesses, researchers, and enthusiasts alike as one of the most powerful natural language processing models currently in existence.
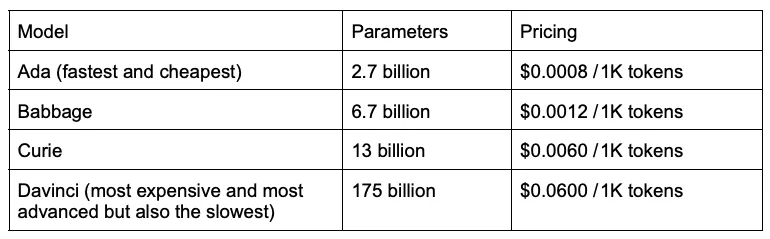
Despite its capabilities and popularity, GPT-3 has some drawbacks in terms of cost, data quality and privacy that make it a less than ideal choice for certain applications. Fortunately, there are several open-source alternatives to GPT-3 that provide similar power with fewer of these drawbacks. In this article we will examine some of the key features of GPT-3 and discuss what open-source alternatives can offer to users that may be looking for more flexible and affordable solutions.
The latest version of the GPT model developed by OpenAI is known as GPT-4 (Generative Pretrained Transformer 4), and it represents a major advancement in the field of natural language processing. Built upon the foundation laid by its predecessor, GPT-3, which was released in May 2020 and quickly gained widespread popularity, GPT-4 is a large-scale machine learning model that has been extensively trained on a vast amount of data in order to generate text that is increasingly similar to human language.
Open source alternatives such as Google’s Bidirectional Encoder Representations from Transformers (BERT) and XLNet are two important contenders when considering Turing complete language models as powerful replacements for GPT-3. Both are trained on huge volumes of unlabeled data from online sources to produce meaningful text generation results with superior accuracy compared to traditional approaches. They also offer fine-grained control over pre-training parameters for user specific needs as well as transfer learning capabilities which allow model customization on domain specific tasks. Finally, their open source nature offers flexibility when it comes to pricing structures for users looking for less expensive compute resources or no usage fees at all.
What is the difference between GPT-3 and GPT-4?
| GPT-3.5 | GPT-4 | |
|---|---|---|
| Release Date | November 2022 | March 2023 |
| Uses | Chatbot Question answering Text summarization | Image and text processing Chatbot Question answering Text summarization |
| Accessibility | Variations available on the OpenAI Playground Available for commercial use via OpenAI pricing plans | Available via Chat GPT Plus subscription Waitlist open access to GPT-4 via OpenAI API |
| Information | Limited knowledge of events after 2021 | Limited knowledge of events after 2021 |
Overview of GPT-3 tool
GPT-3 (Generative Pre-trained Transformer 3) is the third version of OpenAI’s open-source language model. It has been developed by the OpenAI team at large scale on a range of tasks like machine translation, question answering, reading comprehension, and summarization. This AI breakthrough enables applications to predict natural language processing (NLP) with fewer manual steps and better accuracy than previously possible.
GPT-3 can be used to generate text and produce accurate predictions by either learning from few examples or without any training data. This has made it a powerful tool for Natural Language Understanding (NLU), as well as other artificial intelligence applications like optimization or control. The model is built using large datasets in the form of unsupervised learning, where a model learns how to produce answers to questions without requiring any manual input or training data.
The advancements of GPT-3 have been met with interest and praise by many in the research community due to its wide range of capabilities and ability to understand language more holistically and accurately than previously thought possible. However, OpenAI’s open source initiative has sparked debate regarding cloud computing privacy implications associated with its use as well as its potential for misuse in disenfranchising certain languages or communities through biased representations. In response, many have turned to introducing and exploring open-source alternatives to GPT-3 for their Natural Language Processing needs.
Benefits of Open-Source Alternatives to GPT-3
The natural language processing (NLP) industry has been abuzz from the recent commercial release of OpenAI’s Generative Pre-trained Transformer 3 (GPT-3). The massive language model has attracted the attention of both practitioners and enthusiasts alike—due to its potential implications for automation and usability. GPT-3 is an example of a “black box” machine learning model that can be used for many tasks, but its closed source nature limits what users can access.
However, open-source alternatives to GPT-3 are available that offer similar capabilities with the added benefit of being accessible to all. Open source software is freely available, allowing anyone to interrogate its code—allowing transparency and accountability into their processes. Such open source models also provide users with more control over their own data when compared to commercial options.
The advantage of open source software goes beyond mere access; since they are free to modify, they also allow developers to embed important safety measures into their design in order to prevent misuse or abuse of the technology. Additionally, by having multiple versions of a model available at once it allows experts to compare versions and make more informed decisions regarding which model best fits their needs.
Open source alternatives to GPT-3 provide engineers with powerful tools for automation without sacrificing on features or security; allowing them greater freedom and control in developing NLP applications in comparison with closed-source options like GPT-3.
What about ChatGPT?

ChatGPT is a chatbot that can answer questions and imitate a dialogue, it’s built on GPT-3 technology. It was announced by OpenAI in November, as a new feature of GPT-3. The chatbot can understand natural language input and generate human-like responses, making it a powerful tool for customer service, personal assistants, and other applications that require natural language processing capabilities. Some experts say that it could replace Google over time.
According to the SimilarWeb portal, its monthly audience is more than 600 million users. And it’s growing by 40% M2M.
How Does ChatGPT Work?
You’ve probably heard of ChatGPT at this point. People use it to do their homework, code frontend web apps, and write scientific papers. Using a language model can feel like magic; a computer understands what you want and gives you the right answer. But under the hood, it’s just code and data.
When you prompt ChatGPT with an instruction, like Write me a poem about cats, it turns that prompt into tokens. Tokens are fragments of text, like write, or poe. Every language model has a different vocabulary of tokens.
Computers can’t directly understand text, so language models turn the tokens into embeddings. Embeddings are similar to Python lists — they look like this [1.1,-1.2,2,.1,...]. Semantically similar tokens are turned into similar lists of numbers.
ChatGPT is a causal language model. This means it takes all of the previous tokens, and tries to predict the next token. It predicts one token at a time. In this way, it’s kind of like autocomplete — it takes all of the text, and tries to predict what comes next.
It makes the prediction by taking the embedding list, and passing it through multiple transformer layers. Transformers are a type of neural network architecture that can find associations between elements in a sequence. They do this using a mechanism called attention. For example, if you’re reading the question Who is Albert Einstein? , and you want to come up with the answer, you’ll mostly pay attention to the words Who and Einstein.
Transformers are trained to identify which words in your prompt to pay attention to in order to generate a response. Training can take thousands of GPUs and several months! During this time, transformers are fed gigabytes of text data so that they can learn the correct associations.
To make a prediction, transformers turn the input embeddings into the correct output embeddings. So you’ll end up with an output embedding like [1.5, -4, -.1.3, .1,...], which you can turn back into a token.
If ChatGPT is only predicting one token at a time, you might wonder how it can come up with entire essays. This is because it’s autoregressive. This means that it predicts a token, then adds it back to the prompt and feeds it back into the model. So the model actually runs once for every token in the output. This is why you see the output of ChatGPT word by word instead of all at once.
ChatGPT stops generating the output when the transformer layers output a special token called a stop token. At this point, you hopefully have a good response to your prompt.
The cool part is that all of this can be done using Python code! PyTorch and Tensorflow are the most commonly used tools for creating language models. If you want to learn more, check out the Zero to GPT series that I’m putting together. This will take you from no deep learning knowledge to training a GPT model.
Popular Open-Source Alternatives to GPT-3
GPT-3 is an artificial intelligence (AI) platform developed by OpenAI and released in May 2020. GPT-3 is the third and largest version of OpenAI’s language model and was trained on a dataset of 45TB of text. This model can be used for a wide range of natural language applications, such as writing, translation, or summarization. However, given its staggering processing power requirements, not all developers are able to use GPT-3 due to its cost or lack of skill necessary to run it.
Fortunately, there are other open-source alternatives that may be suitable for your project. Below are some popular OpenAI GPT-3 competitors:
- BERT (Bidirectional Encoder Representations from Transformers): BERT is an open-source language representation model developed by Google AI Language research in 2018. It has been pre-trained on more than 40 languages and provides reliable performance across many different tasks like sentiment analysis, question answering, classification etc. It also uses deep learning architectures to process language understanding which makes it suitable for many NLP tasks.
- XLNet: XLNet is an improvement over the pre-existing Transformer encoder system created by Google AI Researchers in June 2019. XLNet outperforms the state of the art on a variety of natural language understanding tasks such as question answering and document ranking while only requiring significantly less training data than BERT.
- ELMo (Embeddings from Language Models): ELMo is a deep contextualized word representation that models both shallow semantic features as well as meaning from context using multi layers objective functions over bidirectional language Models (LMs). ELMo was created by Allen Institute for Artificial Intelligence researcher at University of Washington in 2017. It requires significantly less compute compared with other deep learning models like BERT or GPT-3 while still providing reasonable accuracy too on various NLP tasks like text classifications or entity extraction.
- GPT-Neo (2.7B) – download gpt-neo here GPT-Neo 2.7B was trained on the Pile, a large scale curated dataset created by EleutherAI for the purpose of training this model.
Each alternative has its own advantages and disadvantages when compared against each other so it’s important to carefully assess which one best fits your project before selecting one for use in your application development process.
Comparison of Open-Source Alternatives to GPT-3
In response to OpenAI’s GPT-3, there have been various efforts to develop open-source large-scale language models. A comparison of the most popular open-source alternatives to GPT-3 is given below.
- XLNet: XLNet was developed by researchers at Carnegie Mellon University and Google AI Language. It is a Transformer model which uses a number of different training objectives such as auto-regressive, bidirectional and unidirectional mean squared error. XLNet has achieved strong results on language understanding benchmarks such as GLUE and SQuAD.
- BERT: BERT (Bidirectional Encoder Representations from Transformers) is an open source transformer model initially developed by Google AI in 2018. It has since been applied in many NLP tasks such as question answering, text classification, etc. BERT algorithms achieved impressive results across various NLP tasks such as question answering and natural language inference (QA/NLI). While BERT algorithms are largely effective at transfer learning with pre-trained models, they require very large datasets for adult training which makes them more difficult to replicate than GPT-3’s approach with its 1 trillion parameter pretraining on the web corpus CommonCrawl SQuAD (a collection of questions sourced from Wikipedia).
- TransformerXL: TransformerXL was developed by researchers at both Huawei Noah’s Ark Lab and Carnegie Mellon University. This open source algorithm aims to extend the current context length of Transformer architecture from 512 tokens to thousand or even millions of tokens allowing it to easily learn cross document or long range dependencies between words even though no datasets currently exist for those types of sequences tasks today. This could be one possible solution for machine translation due to its ability to extract longer phrases than compared to BERT or GPT-3 models which only focuses on local context length of 512 tokens maximum per example text sequence inputted into the model itself.
- UmbrellaLM: UmbrellaLM was developed by AppliedResearchInc and released under Apache Licensed 2.0 recently in 2021 while leveraging DistilBERT pretraining approaches from HuggingFace Transformers library as well as OpenAI’s GPT2 algorithms for text understanding tasks based off easily fine tuning pretrained weights using extremely small datasets (<50MB) compared against having all models trained from scratch based off traditional large scale TextCorpus datasets (>1GB).
Challenges Associated with Open-Source Alternatives to GPT-3
Given that GPT-3 has been developed by a well-funded organization, open-source alternatives have faced numerous challenges in order to compete. One major challenge is the fact that labelling the training data for these alternatives often involves much more manual effort, whereas GPT-3 was trained on human-written data from sources such as books, Wikipedia, and Reddit.
Another major challenge for open-source alternatives to GPT-3 is scalability. In order to train larger networks and keep up with GPT-3’s performance, more computational power is needed. This can be difficult for a lesser funded organization to acquire as they may not have access to the same resources that OpenAI has at its disposal.
Finally, developing state-of-the art NLP models requires significant human resources – something most open source projects don’t have access to in large enough quantities. While many NLP tasks may be simple enough to be handled by passionate volunteers and interns working part time, there are still certain areas that require highly skilled professionals who may not always be available or willing to contribute their services on an unpaid basis. As a result, only experienced developers with job security can tackle ambitious projects such as creating an alternative to GPT-3 without running into any financial constraints in the long run.
Best Practices for Using Open-Source Alternatives to GPT-3
GPT-3 is a large, state-of-the-art language model released by OpenAI with remarkable performance in many tasks without any labeled training data. Unfortunately, the cost of using GPT-3 models can be prohibitive for many businesses and organizations, making open source alternatives an attractive option. Here are some best practices to consider when using open source alternatives to GPT-3 in your projects:
- Select the right model architecture: Before selecting an alternative to GPT-3 as your language model, it is important to assess the different architectures that are available and select one that is suitable for your project. Larger models are not always better, as even mid-sized models can often be more efficient or provide adequate performance for certain applications. Other important factors to consider include how well existing knowledge can be leveraged within your project context, how quickly improvements in accuracy can be expected with additional data, and the difficulty of training on new data or setting hyperparameters.
- Consider pre-trained language models: Many open source alternatives come pre-trained on public datasets (e.g., Wikipedia). These can help accelerate projects as no additional training time is needed and they are often suitable for many use cases without modifications. However, they may not offer enough accuracy in specific contexts if fine-tuning them based on specialized data sets is possible and practical – this trade off between time and accuracy should always be weighed up when selecting a model.
- Pay attention to documentation and tutorials: When using open source language models it’s important to pay attention to available documentation and tutorials related to the architecture you’ve chosen — this will help you get up to speed quickly with its implementation (i.e., inference) requirements/steps/options which might not be as straightforward as those used by GPT-3 from OpenAI’s API platform.
- Document results & collect feedback: Finally, when beginning any ML project it’s important to document results thoroughly — tracking errors or validations for each step including hyperparameter optimization — so that optimizations could be done easily later on; also properly gather user feedback whenever possible as this helps inform decisions around future implementations/improvements of your system’s architecture.
Conclusion: GPT-3/4 open-source alternative
In conclusion, GPT-3/4 is a remarkable language model that has pushed the boundaries of natural language processing. However, not everyone may have access to its commercial version for their project’s requirements. Fortunately, there are several excellent open-source alternatives to GPT-3 which are likewise capable of delivering comparable performance, but at a fraction of the cost and complexity.
These include models such as ELMo, BERT, XLNet and ALBERT. Each model has its own unique strengths and weaknesses which should be considered when selecting the most suitable model for a given task. Additionally, more research will no doubt continue to improve these models as time goes on.
Therefore these open-source language models provide an excellent solution in developing applications that require natural language processing with outstanding performance at a low cost.
Reference Links:
- BigScience Workshop https://bigscience.huggingface.co/
- https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html
- https://huggingface.co/docs/transformers/model_doc/bloom
- https://github.com/EleutherAI/gpt-neox/
- https://openai.com/
- GPT-J-6B https://6b.eleuther.ai/
GPT freelance developers are available for hire to utilize this language model for building diverse tools and applications, which provides an opportunity for everyone to create with GPT-3/3,5/4.
Recommendation to Read
“Profession” Novella by Isaac Asimov.








Preventing Local Malware Injection in AI Apps
Blur Card – Crypto Cards with Hidden Fees

Nudefusion AI App Review
ControlNet: Revolutionizing Neural Control in AI Image Generation
PayPal Sports Betting Guide for Beginners
Nudefusion AI App Review
ControlNet: Revolutionizing Neural Control in AI Image Generation