Crawling and Scraping
Comparison of Open Source Web Crawlers for Data Mining and Web Scraping: Pros&Cons

Data mining and web scraping are two important tasks for anyone looking to gather data from the internet. There are a number of open-source web crawlers available to help with these tasks, but which one is the best?
[entity_list id=”17689″]
In this blog post, we compare the pros and cons of the most popular open source web crawlers to help you make the best decision for your needs.
The Best open-source Web Crawling Frameworks in 2025
In my search for a suitable back-end crawler for my startup, I looked at many open source solutions. After some initial research, I narrowed the choice down to the 10 systems that seemed to be the most mature and widely used:
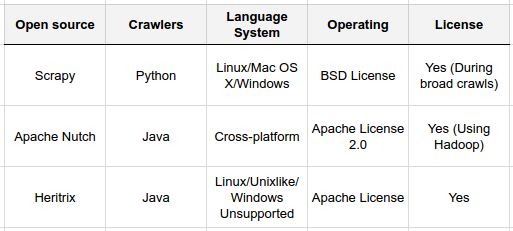
- Scrapy (Python),
- Heritrix (Java),
- Apache Nutch (Java),
- PySpider (Python),
- Web-Harvest (Java),
- MechanicalSoup (Python),
- Apify SDK (JavaScript),
- Jaunt (Java),
- Node-crawler (JavaScript),
- StormCrawler (Java).
What is the best open source Web Crawler that is very scalable and fast?
As a starting point, Web crawling is the process by which we gather pages from the Web, in order to index them and support a search engine.
I wanted the crawler services of choice to satisfy the properties described in Web crawling and Indexes:
- Robustness: The Web contains servers that create spider traps, which are generators of web pages that mislead crawlers into getting stuck fetching an infinite number of pages in a particular domain. Crawlers must be designed to be resilient to such traps. Not all such traps are malicious; some are the inadvertent side-effect of faulty website development.
- Politeness: Web servers have both implicit and explicit policies regulating the rate at which a crawler can visit them. These politeness policies must be respected.
- Distributed: The crawler should have the ability to execute in a distributed fashion across multiple machines.
- Scalable: The crawler architecture should permit scaling up the crawl rate by adding extra machines and bandwidth.
- Performance and efficiency: The crawl system should make efficient use of various system resources including processor, storage and network band-width.
- Freshness: In many applications, the crawler should operate in continuous mode, obtaining fresh copies of previously fetched pages. A search engine crawler, for instance, can thus ensure that the search engine’s index contains a fairly current representation of each indexed web page. For such continuous crawling, a crawler should be able to crawl a page with a frequency that approximates the rate of change of that page.
- Quality: Given that a significant fraction of all web pages are of poor utility for serving user query needs, the crawler should be biased towards fetching “useful” pages first.
- Extensible: Crawlers should be designed to be extensible in many ways — to cope with new data formats, new fetch protocols, and so on. This demands that the crawler architecture be modular.
terms of various parameters (IJSER)
I also had a wish list of additional features that would be nice to have. Instead of just being scalable I wanted to the crawler to be dynamically scalable, so that I could add and remove machines during continuous web crawls. I also wanted the crawler to export data into various storage backends or data pipelines like Amazon S3, HDFS, or Kafka.

Focused vs. Broad Crawling
Before getting into the meat of the comparison let’s take a step back and look at two different use cases for web crawlers: Focused crawls and broad crawls.
In a focused crawl you are interested in a specific set of pages (usually a specific domain). For example, you may want to crawl all product pages on amazon.com. In a broad crawl the set of pages you are interested in is either very large or unlimited and spread across many domains. That’s usually what search engines are doing. This isn’t a black-and-white distinction. It’s a continuum. A focused crawl with many domains (or multiple focused crawls performed simultaneously) will essentially approach the properties of a broad crawl.
Now, why is this important? Because focused crawls have a different bottleneck than broad crawls.
When crawling one domain (such as amazon.com) you are essentially limited by your politeness policy. You don’t want to overwhelm the server with thousands of requests per second or you’ll get blocked. Thus, you need to impose an artificial limit of requests per second. This limit is usually based on server response time. Due to this artificial limit, most of the CPU or network resources of your server will be idle. Having a distributed crawler using thousands of machines will not make a focused crawl go any faster than running it on your laptop.
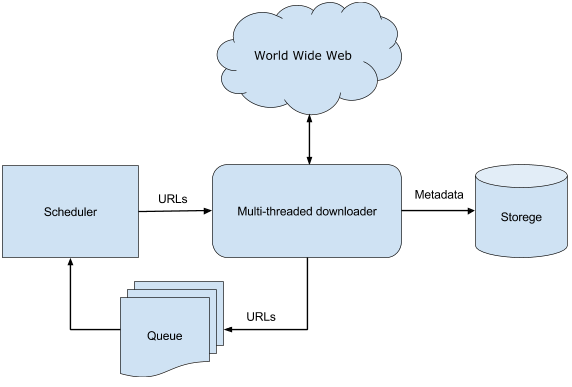
In the case of broad crawl, the bottleneck is the performance and scalability of the crawler. Because you need to request pages from different domains you can potentially perform millions of requests per second without overwhelming a specific server. You are limited by the number of machines you have, their CPU, network bandwidth, and how well your crawler can make use of these resources.
If all you want it scrapes data from a couple of domains then looking for a web-scale crawler may be overkill. In this case take a look at services like import.io (from $299 monthly), which is great at scraping specific data items from web pages.
Scrapy (described below) is also an excellent choice for focused crawls.


Scrapy
Website: http://scrapy.org
Language: Python
Scrapy is a Python framework for web scraping. It does not have built-in functionality for running in a distributed environment so that it’s primary use case are focused crawls. That is not to say that Scrapy cannot be used for broad crawling, but other tools may be better suited for this purpose, particularly at a very large scale. According to the documentation the best practice to distribute crawls is to manually partition the URLs based on domain.
What stands out about Scrapy is its ease of use and excellent documentation. If you are familiar with Python you’ll be up and running in just a couple of minutes.
Scrapy has a couple of handy built-in export formats such as JSON, JSON lines, XML and CSV. Scrapy was built for extracting specific information from websites, not necessarily getting for a full dump of the HTML and indexing it. The latter requires some manual work to avoid writing the full HTML content of all pages to one gigantic output file. You would have to chunk the files manually.
Without the ability to run in a distributed environment, scale dynamically, or run continuous crawls, Scrapy is missing some of the key features I was looking for. However, if you need easy to use tool for extracting specific information from a couple of domains then Scrapy is nearly perfect. I’ve successfully used it in several projects and have been very happy with it.
Pros:
- Easy to setup and use if you know Python
- Excellent developer documentation
- Built-in JSON, JSON lines, XML and CSV export formats
Cons:
- No support for running in a distributed environment
- No support for continuous crawls
- Exporting large amounts of data is difficult
How to develop a custom web crawler on Python for OLX? You can do it by guide from Adnan.
Heritrix
Website: webarchive.jira.com
Language: Java
Heritrix is developed, maintained, and used by The Internet Archive. Its architecture is described in this paper and largely based on that of the Mercator research project. Heritrix has been well-maintained ever since its release in 2004 and is being used in production by various other sites.
Heritrix runs in a distributed environment by hashing the URL hosts to appropriate machines. As such it is scalable, but not dynamically scalable. This means you must decide on the number of machines before you start crawling. If one of the machines goes down during your crawl you are out of luck.
The output format of Heritrix are WARC files that are written to the local file system. WARC is an efficient format for writing multiple resources (such as HTML) and their metadata into one archive file. Writing data to other data stores (or formats) is currently not supported, and it seems like doing so would require quite a few changes to the source code.
Continuous crawling is not supported, but apparently it is being worked on. However, as with many open source projects the turnaround time for new features can be quite long and I would not expect support for continuous crawls to be available anytime soon.
Heritrix is probably the most mature out of the source projects I looked it. I have found it easier to setup, configure and use than Nutch. At the same time it is more scalable and faster than scrapy. It ships together with a web frontend that can be used for monitoring and configuring crawls.
Pros:
- Excellent user documentation and easy setup
- Mature and stable platform. It has been in production use at archive.org for over a decade
- Good performance and decent support for distributed crawls
Cons:
- Does not support continuous crawling
- Not dynamically scalable. This means, you must decide on the number of servers and partitioning scheme upfront
- Exports ARC/WARC files. Adding support for custom backends would require changing the source
Further Reading:
- An introduction to Heritrix (2004)
- Incremental crawling with Heritrix (2005)
- A vertical search engine for school information based on Heritrix and Lucene (2011)

Apache Nutch
Website: nutch.apache.org
Language: Java
Instead of building its own distributed system Nutch makes use of the Hadoop ecosystem and uses MapReduce for its processing ( details ). If you already have an existing Hadoop cluster you can simply point Nutch at it. If you don’t have an existing Hadoop cluster you will need to setup and configure one. Nutch inherits the advantages (such as fault-tolerance and scalability), but also the drawbacks (slow disk access between jobs due to the batch nature) of the Hadoop MapReduce architecture.
It is interesting to note that Nutch did not start out as a pure web crawler. It started as an open-source search engine that handles both crawling and indexing of web content. Even though Nutch has since become more of a web crawler, it still comes bundled with deep integration for indexing systems such as Solr (default) and ElasticSearch(via plugins). The newer 2.x branch of Nutch tries to separate the storage backend from the crawling component using Apache Gora, but is still in a rather early stage. In my own experiments I have found it to be rather immature and buggy. This means that if you are considering using Nutch you will probably be limited to combining it with Solr and ElasticSearch Web Crawler, or write your own plugin to support a different backend or export format.
Despite a lot of prior experience with Hadoop and Hadoop-based projects I have found Nutch quite difficult to setup and configure, mostly due to a lack of good documentation or real-world examples.
Nutch (1.x) seems to be a stable platform that is used in production by various organization, CommonCrawl among them. It has a flexible plugin system, allowing you to extend it with custom functionality. Indeed, this seems to be necessary for most use cases. When using Nutch you can expect spending quite a bit of time writing your own plugins or browsing through source code to make it fit your use case. If you have the time and expertise to do so then Nutch seems like a great platform to build upon.
Nutch does not currently support continuous crawls, but you could write a couple of scripts to emulate such functionality.
Pros:
- Dynamically scalable (and fault-tolerant) through Hadoop
- Flexible plugin system
- Stable 1.x branch
Cons:
- Bad documentation and confusing versioning. No examples.
- Inherits disadvantages of Hadoop (disk reads, difficult setup)
- No built-in support for continuous crawls
- Export limited to Solr/ElasticSearch (on 1.x branch)
Further reading:
PYSpider Web Crawler
PYSpider has been regarded as a robust web crawler open source developed in Python. It has a distributed architecture with modules like fetcher, scheduler, and processor.
Some of its basic features include:
- It has a powerful web-based User Interface with which scripts can be edited and an inbuilt dashboard that provides functionalities like task monitoring, project management, and results viewing and conveys which part is going wrong.
- Compatible with JavaScript and heavy AJAX websites.
- It can store data with supported databases like MYSQL, MongoDB, Redis, SQLite, and ElasticSearch.
- With PYSpider, RabbitMQ, Beanstalk, and Redis can be used as message queues.
Advantages:
- It provides robust scheduling control.
- It supports JavaScript-based website crawling.
- It provides many features, such as an understandable web interface to use and a different backend database.
- It provides support to databases like SQLite, MongoDB, and MYSQL. o It facilitates faster and easier to handle scraping.
Disadvantages:
- Its deployment and setup are a bit difficult and time taking.
Documentation: http://docs.pyspider.org/
Conclusion
Open-source web scrapers are quite powerful and extensible but are limited to developers.
Not surprisingly, there isn’t a “perfect” web crawler out there. It’s all about picking the right one for your use case. Do you want to do a focused or a broad crawl? Do you have an existing Hadoop cluster (and knowledge in your team)? Where do you want your data to end up in?
Out of all the crawlers I have looked at Heritrix is probably my favorite, but it’s far from perfect. That’s probably why some people and organizations have opted to build their own crawler instead. That may be a viable alternative if none of the above fits your exact use case. If you’re thinking about building your own, I would highly recommend reading through the academic literature on web crawling, starting with these:
- Web crawling and indexes (from the “Introduction to Information Retrieval” book)
- Web crawling survey (2010)
- High-Performance web crawling (Mercator)
- UbiCrawler: A Scalable Fully Distributed Web Crawler
What are your experiences with web crawlers? What are you using and are you happy with it? Did I forget any? I only had limited time to evaluate each of the above crawlers, so it is very possible that I have overlooked some important features. If so, please let me know in the comments.
Do you Know What Google use Java?
Need Top 50 open source web crawlers List for data mining?





Preventing Local Malware Injection in AI Apps
Blur Card – Crypto Cards with Hidden Fees

Nudefusion AI App Review
ControlNet: Revolutionizing Neural Control in AI Image Generation
PayPal Sports Betting Guide for Beginners
Nudefusion AI App Review
Blur Card – Crypto Cards with Hidden Fees
Agribusiness Global Allies
2018-03-01 at 23:12
Thanks, your article saved a lot of reading elsewhere. Are there folks out there interested in building a bespoke crawler (for a specific purpose)?
Alex
2018-03-01 at 23:16
Hi! Yes, these guys gbksoft.com can help with a custom crawler.
Jorge Luis
2018-03-01 at 23:14
I would recommend that you can add StormCralwer (https://github.com/DigitalPebble/storm-crawler/) also to the comparison, is a bit different because is not thought as an out of the box crawler but as a set of components that you can glue together for your own use case. But, that being said I think that it could be included in your comparison.
Alex
2018-03-01 at 23:16
Jorge, Thanks for the recommendation.
Shailesh Jain
2018-03-01 at 23:20
Thank you for this article. I’m looking at building a topical crawler (across multiple domains) which can basically create an index of web pages based on topics. Any recommendations?
Alex
2018-03-01 at 23:21
There is a lot of information on the Internet. But I recommend you check idea with this tools for multiple domains search https://cse.google.com/cse/all before start development.
Thilo Haas
2018-03-01 at 23:31
Thank you for this extensive comparison! We found Apache Nutch to be the best match for our use case. Documentation is the biggest pain point but if you deep dive into the source code its fairly easy to get things running and get the most out of it since most use cases are already handled by Nutch Plugins although not documented.. I wrote about our outcomes here: https://blog.smartive.ch/replace-google-gsa-with-a-custom-search-engine-and-crawler-813838691a2
Alex
2018-03-01 at 23:31
Thank you, Thilo Haas! I hope to see more on web crawler topic by smartive team in future!
Eric Pugh
2018-03-01 at 23:32
Your article speaks to the rather sad state of affairs for web crawling. Nutch 1 is complex, and Nutch 2 isn’t ready for normal users. Heritrix is rather dated these days. Scrapy is pretty modern, but it’s really a scraper, not a crawler… .
For a good crawler, you are back to using commercially supported products.
So far, I haven’t seen any crawlers that truly could emulate a browser either, and so much of the web requires JavaScript… .
I was pretty excited about SpookyStuff (https://github.com/tribbloid/spookystuff), however it seems to have veered off recently to being a tool for controlling drones??!!!
Alex
2018-03-01 at 23:32
Open source Products have always had their limits. I agree that paid solutions can be more successful.
Aditya Patel
2018-10-01 at 09:38
Its very nice article. thanks for sharing such great compar article. keep sharing such kind of article.
swethakapoor
2018-12-11 at 05:02
Reading this article was an experience. I enjoyed all the information you provided and appreciated the work you did in getting it written. You really did a lot of research.
David
2019-10-09 at 21:25
Crawling and indexing are two distinct things and this is commonly misunderstood in the SEO industry. Crawling means that Googlebot looks at all the content/code on the page and analyzes it. Indexing means that the page is eligible to show up in Google’s search results. No matter how fast your website’s load, or how detailed your content is, still, it doesn’t matter if it is not index on Google SERP.
Bas
2019-11-02 at 08:53
Scrapy does support continuous crawling, with an addiotional tool called Frontera (made available by the same company, like an orchestration kind of tool)
Administrasi Bisnis
2023-06-24 at 00:53
What are your experiences with web crawlers?