Edtech
How to Produce a DeepFake Video with Putin in 5 Minutes
Everybody can make DeepFakes to support ukrainians without writing a single line of code.
In this story, we see how image animation technology is now ridiculously easy to use, and how you can animate almost anything you can think of.
Top Methods To Create A DeepFake Video
Deepfakes are videos that are created using an AI software which makes the person in the video look like they’re saying something that they didn’t say. They often involve celebrities and politicians.
In 2018, deepfakes became a popular topic on social media when it was revealed that one of the best deepfake creators, a Reddit user who goes by “deepfakes,” had used their skills to create a fake video of former president Barack Obama.
This video was made using an AI software called FakeApp which is free to use for non-commercial purposes.
Deep Fakes Are Here and Nobody Knows How to Deal with Them Yet!
Deep fakes are a new kind of media that is being used to manipulate videos and images. They are created by combining different pieces of media and recreating them with deep learning algorithms. Deep fakes have the potential to cause a lot of harm but they can also be used for good.
This article will explore the ways in which deep fakes can be used for both good and bad.
Methodology and Approach
Before creating our own sequences, let us explore this approach a bit further. First, the training data set is a large collection of videos. During training, the authors extract frame pairs from the same video and feed them to the model. The model tries to reconstruct the video by somehow learning what are the key points in the pairs and how to represent the motion between them.
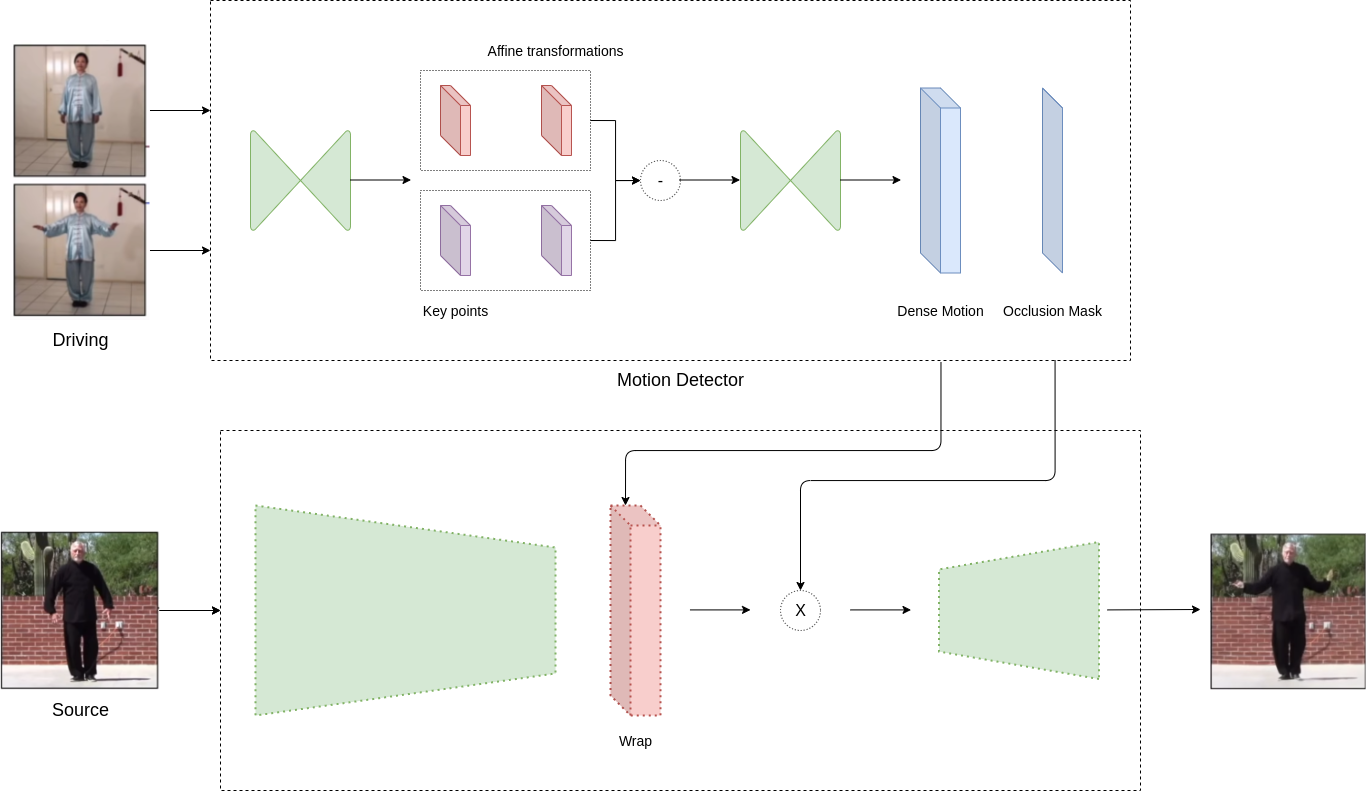
To this end, the framework consists of two models: the motion estimator and the video generator. Initially, the motion estimator tries to learn a latent representation of the motion in the video. This is encoded as motion-specific key point displacements (where key points can be the position of eyes or mouth) and local affine transformations. This combination can model a larger family of transformations instead of only using the key point displacements. The output of the model is two-fold: a dense motion field and an occlusion mask. This mask defines which parts of the driving video can be reconstructed by warping the source image, and which parts should be inferred by the context because they are not present in the source image (e.g. the back of the head). For instance, consider the fashion GIF below. The back of each model is not present in the source picture, thus, it should be inferred by the model.

Next, the video generator takes as input the output of the motion detector and the source image and animates it according to the driving video; it warps that source image in ways that resemble the driving video and inpatient the parts that are occluded. Figure 1 depicts the framework architecture.
Code Example
The source code of this paper is on GitHub. What I did is create a simple shell script, a thin wrapper, that utilizes the source code and can be used easily by everyone for quick experimentation.
To use it, first, you need to install the module. Run pip install deep-animator to install the library in your environment. Then, we need four items:
- The model weights; of course, we do not want to train the model from scratch. Thus, we need the weights to load a pre-trained model.
- A YAML configuration file for our model.
- A source image; this could be for example a portrait.
- A driving video; best to download a video with a clearly visible face for start.
To get some results quickly and test the performance of the algorithm you can use this source image and this driving video. The model weights can be found here. A simple YAML configuration file is given below. Open a text editor, copy and paste the following lines and save it as conf.yml.
model_params:
common_params:
num_kp: 10
num_channels: 3
estimate_jacobian: True
kp_detector_params:
temperature: 0.1
block_expansion: 32
max_features: 1024
scale_factor: 0.25
num_blocks: 5
generator_params:
block_expansion: 64
max_features: 512
num_down_blocks: 2
num_bottleneck_blocks: 6
estimate_occlusion_map: True
dense_motion_params:
block_expansion: 64
max_features: 1024
num_blocks: 5
scale_factor: 0.25
discriminator_params:
scales: [1]
block_expansion: 32
max_features: 512
num_blocks: 4
Now, we are ready to have a statue mimic Leonardo DiCaprio! To get your results just run the following command.
deep_animate <path_to_the_source_image> <path_to_the_driving_video> <path_to_yaml_conf> <path_to_model_weights>
For example, if you have downloaded everything in the same folder, cd to that folder and run:
deep_animate 00.png 00.mp4 conf.yml deep_animator_model.pth.tar
On my CPU, it takes around five minutes to get the generated video. This will be saved into the same folder unless specified otherwise by the --dest option. Also, you can use GPU acceleration with the --device cuda option. Finally, we are ready to see the result. Pretty awesome!

Conclusion
I this story, we presented the work done by A. Siarohin et al. and how to use it to obtain great results with no effort. Finally, we used deep-animator, a thin wrapper, to animate a statue.







How to Set Up Text-to-Speech for Channel Points on Twitch

The Average Size of Home Office: A Perfect Workspace
Top 10 Best Fake ID Websites [OnlyFake?]

How Much Does a Hosting Server Cost Per User for an App?
How Gaming Technologies are Transforming the Entertainment Industry
What is my Instagram URL? How to Find & Copy Address [Guide on Desktop or Mobile]

Applob.com Download APK – Tweak your device Safe

About Apple Employee and Friends&Family Discount in 2024
How to Translate more 5,000 characters limit by Google

How to Unlist your Phone Number from GetContact
-
 Cyber Risk Management3 days ago
Cyber Risk Management3 days agoHow Much Does a Hosting Server Cost Per User for an App?
-

 Outsourcing Development3 days ago
Outsourcing Development3 days agoAll you need to know about Offshore Staff Augmentation
-

 Software Development3 days ago
Software Development3 days agoThings to consider before starting a Retail Software Development
-
 Grow Your Business3 days ago
Grow Your Business3 days agoThe Average Size of Home Office: A Perfect Workspace
-
Solution Review3 days ago
Top 10 Best Fake ID Websites [OnlyFake?]
-
Business Imprint3 days ago
How Gaming Technologies are Transforming the Entertainment Industry
-
 Gaming Technologies1 day ago
Gaming Technologies1 day agoHow to Set Up Text-to-Speech for Channel Points on Twitch